728x90
1. 엔티티
- 현황:AS-IS
- 개념 모델링 (분석)
- 기존 ERD, DB
- 업무 메뉴얼
- 시스템 메뉴얼
- ER 모델 구성 요소 : 엔티티, 관계, 속성
- 엔티티 : 실제로 존재하는 실체이거나 , 서비스, 조직, 직업처럼 개념적인 것
- 엔티티와 엔티티 type
- 엔티티 type: 사람 - table명 느낌이 강함
- 엔티티 : 김철수 - instance 느낌이 강함
1.1. 엔티티 표기법
- 기본 표기법

- 엔티티 슈퍼타입 / 서브타입 표기법

1.2. 일반화
- 개념
- 일반화: 엔티티 각각이 가지고 있는 고유한 특징을 일반화하여 공통의 속성으로 재정의 한 것
- 종류
- 하위 수준 엔티티
- 상위 수준 엔티티
1.2.1. 하위 수준 엔티티 일반화


- 설명
- 방식1 : 개인, 법인에 찾아들어가서 고객 정보를 가져와야한다. 중복 존재가능성이 존재
- 방식2 : 고객정보를 가지고 오기 쉽다. 고객 정보중 각 유형의 정보를 가지고 올 경우 join을 해야한다.
- 반달에 x 표시는 배타적인 것을 의미
1.2.2. 상위 수준과 하위 수준 엔티티의 일반화

- 대-중-소
- 방식1 ( 추천 )
- 정적=고정
- 1단계 2단계 3단계로 추가 될 수 있다.
- 해당 방식을 이용하는 것을 추천
- 방식2
- table이 자기자신과의 관계
- self join
1.2.3. 고객 일반화
그런게 있다 정도
- 배타 관계 주의점
- system 구축시 배타 관계로 인해 UNION이나, Outer Join을 사용하는 경우가 종종 발생
- 그렇게 하기 싫어서 통합 table 만드는 경우
- 장점 : UNION 이나 Outer Join 할 필요 없이 개발 생산성이 증가 및 성능 향상 효과 기대
- 단점 : FK 제약조건이나 Not Null 제약 조건을 반영할 수 없어서 데이터 무결성 문제가 발생
1.3. 특수화
- 일반화의 반대 개념으로, 하나의 상위 수준 엔티티를 2개 이상의 하위 수준 엔티티로 분할하는 하향식 접근 방식
1.4. 집단화
1.5. 다양한 엔티티 분류
- 엔티티 관계
- 강한
- 약한
- 엔티티 형태
- 독립 엔티티
- 업무중심 엔티티
- 종속 엔티티
- 교차 엔티티
- n : n 관계의 entity는 무조건 중복이 발생하는 문제가 생긴다. 따라서 교차 테이블을 이용해서 중복을 해소(반드시)해야한다.
- 수강생(n) : 수강과목(n) - bad
수강생(1) : [수강생, 수강 과목] (n) : 수강 과목 (1)

- 엔티티 생성 관점
- 핵심
- 중요
- 행위
- 엔티티 유무형
- 실체
- 비실체
- 개념
- 사건
2. 관계
- 암기 3가지
- 관계수 1 : 1 or 1 : n
- 관계 선택성 필수 값 혹은 선택 가능한 값
- 식별성 FK가 PK인 경우
- 표기법

2.1. 관계수
- 관계수 : 어떤 엔티티의 인스턴스 하나가 다른 엔티티 몇 개의 인스턴스와 대응될 수 있는지 표현 / 까마귀 발로 표현
- 관계수 종류
- 1:1 관계
- 개인 정보 - 마이페이지
- 관련 예제를 찾기가 힘듬 -> 거의 존재 안한다고 생각해도 될 듯
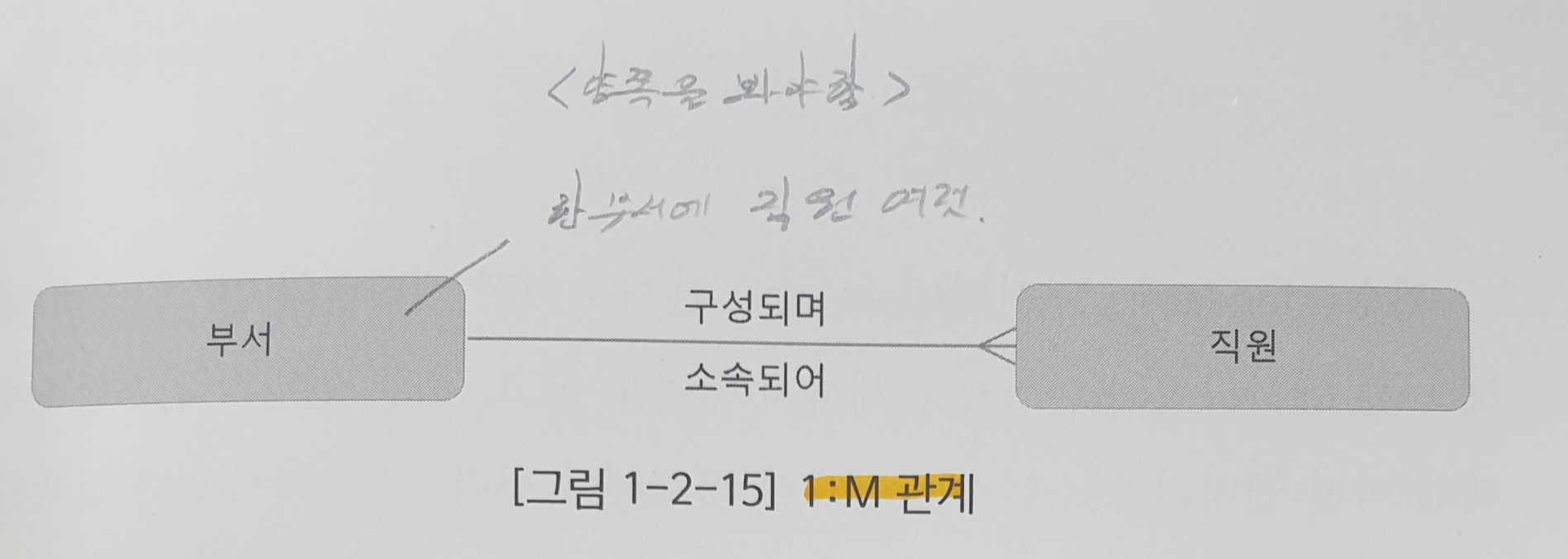

2.2. 관계 선택성
필수는 | 로만 표시

필수 선택 관계 : 자기존재 여부가 다른 table의 필수가 아닌 경우 자기 쪽에 O 표시

선택 선택 관계

2.3. 식별자
필수 선택 관계
- 식별 관계 : pk=fk 인 경우 실선
- 비식별 관계 : pk != fk인 경우, fk가 존재하지만 key로 사용 되지 않는 경우

2.4. 관계유형
- 기본관계
- 제귀적 관계
- 병렬관계 : 엔티티와 엔티티 간에 2개 이상의 관계
- 병렬관계와 엔티티 추가 설계: 병렬 관계가 너무 복잡할 경우 관계의 복잡도를 조금이나마 줄일려는 노력
- 배타적 관계
2.5. 관계 차원
- 단항, 이항, 삼항
- 대부분 2항
3. 속성
- 하나의 엔티티는 2개 이상의 속성을 가지며,
1. 속성명
2. 식별자 여부(pk or not)
3. 옵셔널리티(not null)
4. 도메인(속성이 가질 수 있는 범위 - check)
- 도메인 : check로 범위 지정, 학년이면 1~6 학년, 시간이면 1~24h
- 속성자의 값의 구성이나 성격에 따른 분류
- 단순 속성 - 복합 속성(사실 복합 속성 같은 건 없다)
- 저장 속성 - 파생속성 (중요)
- 단일값 - 다중값
3.1. 파생 속성
- 파생속성
- 성능적인 목적 등 특수한 경우를 제외하고는 별도로 도출하지 않는 것 ;
- 속성으로 저장하지 않는다.
- 예 - 주문 금액 = 단가 * 수량
- 위와 같은 계산 되어서 나오는 것은 저장할 필요가 없고 자주 바뀌기도 한다. - competed column이라고 한다.
- 계산이 너무 복잡하여 성능이 나오지 않을 경우 저장하기도 한다.
3.2. 복합 속성
- 다중 값
- 원래는 안됨, 별도의 table로 분리가 원칙, 경우에 따라서 허용
4. 식별자
- pk를 선택하는 것
- 엔티티에서 인스턴스(row)를 개별적으로 식별할 수 있는 속성
- 유일성(unique), 최소성(column 적게 만들기), 불변성(최대한 변경 불가), 존재성(not null)
- 본질 식별자와 인조 식별자
- 본질 식별자: 존재하는 column에서 선택
- 인조 식별자: sequence